
みなさんはデータを平滑化する際に、どんな方法を用いますか?
簡単な方法だと移動平均などでしょうか。
今回はデータを平滑化する際に、なるべく外れ値の影響を受けずに平滑化する方法を紹介します。
始めにサンプルコードとサンプルデータを置いておきます。
サンプルデータのダウンロードはこちら
import matplotlib.pyplot as plt
import statsmodels.api as sm
import pandas as pd
csv_data = pd.read_csv("C://Users//hogehoge//sin_noise.csv", header=None)
time = csv_data[0]
signal = csv_data[1]
# ロバスト局所回帰 (LOESS) モデルを作成
lowess = sm.nonparametric.lowess
# frac: ウィンドウサイズ、it: ロバスト回帰の反復回数
y_1 = lowess(signal, time, frac=0.05, it=1)
y_10 = lowess(signal, time, frac=0.05, it=10)
y_100 = lowess(signal, time, frac=0.05, it=100)
#結果の描画
col = 2
row = 2
lw = 1
fig, ax = plt.subplots(row, col, tight_layout=True)
ax[0, 0].plot(time, signal, label='Original Data', color='black', linewidth = lw)
ax[0, 1].plot(y_1[:, 0], y_1[:, 1],label='1 roop', color='red', linewidth = lw)
ax[1, 0].plot(y_10[:, 0], y_10[:, 1],label='10 roop', color='blue', linewidth = lw)
ax[1, 1].plot(y_100[:, 0], y_100[:, 1],label='100 roop', color='green', linewidth = lw)
for i in list(range(0, row)):
for j in list(range(0, col)):
ax[i, j].legend()
ax[i, j].set_xlabel('X')
ax[i, j].set_ylabel('Y')
plt.show()目次
- 実装方法
- 挙動の紹介
実装方法
今回使用するのはstatsmodelsライブラリです。
インストールされていない方はインストールしてください。
pip install statsmodelsあとは数行のコードで実装できます。
import statsmodels.api as sm
lowess = sm.nonparametric.lowess # ロバスト局所回帰 (LOESS) モデルを作成
smooth = lowess(Yデータ, Xデータ, frac=ウィンドサイズ, it=反復回数)csvなどから読み取ったデータをXデータ、Yデータにリストなどで指定します。
csvからデータを読み取る方法はこちらを参考にしてください。
挙動の紹介
今回紹介した方法は外れ値を含むデータに強い方法です。
詳しいアルゴリズムは分からないのでこちらを参考にしていただければと思います。

データのフィルター処理と平滑化
- MATLAB & Simulink
- MathWorks 日本
移動平均、Savitzky-Golay フィルター、重みやロバスト性を使用するまたは使用しない局所回帰 (lowess、loess、rlowess および rloess) を使用した、関数 smooth による応答データの平滑化。
jp.mathworks.com
今回使用したサンプルデータはこちらです。
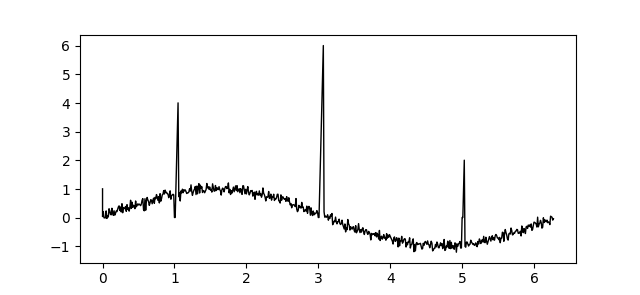
このデータに対してウィンドウの大きさと反復回数を変えて平滑化してみます。
結果がこちら
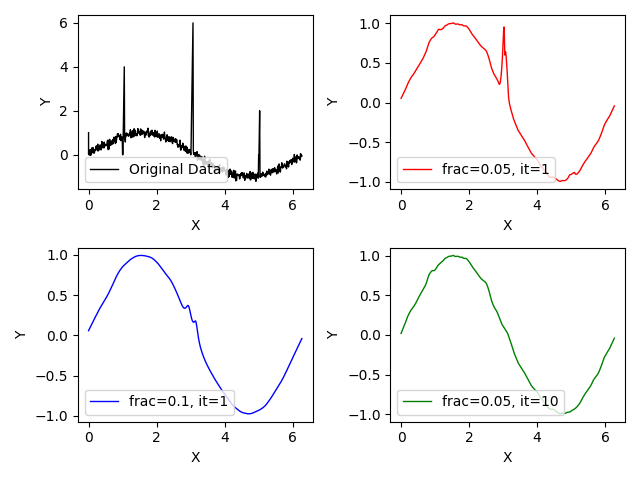
ウィンドウの大きさを大きくするか反復回数を増やすことでより滑らかにできることがわかります。
大きな外れ値の影響を抑えて平滑化できていることがわかります。
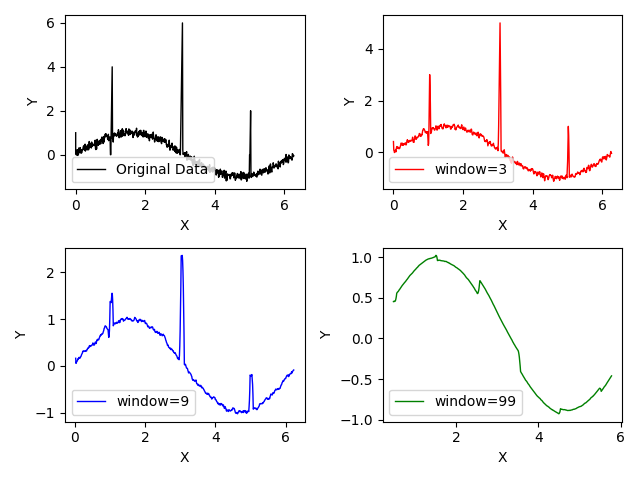
通常の移動平均ではこのような大きな外れ値に大きく影響を受けてしまいます。
強引に平滑化するためにウィンドウを大きくするとガタガタになってしまいます。
おわりに
今回は以上です。
今回の方法は数行のコードで簡単に実装できます。
大きな外れ値を含むデータを扱うときにぜひ使ってみてください。

コメントを残す コメントをキャンセル