
本記事では、Pythonで同じ処理を繰り返したいときに使う構文、for文について解説します。
目次
for文の基本
for文の基本的な書き方
for文の基本的な書き方は次の通りです。

例えばこのように書きます。
for i in range(10): #for i「変数」 in range(10)「中身を1つずつ取り出せるもの」:
print(i) #処理変数はそのまま、for文内の処理で使用する変数です。
次に、inの後ろに「中身を1つずつ取り出せるもの」を書きます。
サンプルコードの例ではrange(10)、つまり0~9の整数です。
ここに何を書くかがセンスが問われるところかと思います。
そして注意点ですが、for文の中に書く処理はforの行から1段下げて書いてください。
Pythonはコードの見た目が処理に影響するので、for文内での処理部分は忘れずに段落を下げましょう!
for内で使う変数について
inの後ろに記述する内容ですが、ここには「中身を1つずつ取り出せるもの」を書くと説明しました。
よく使うのはリストやrange()かと思います。
先ほどご紹介したコードをrange()とリストを使って書くとそれぞれ次のようになります。
for i in range(10): #inの後にrange()を書く
print(i)
for i in [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]: #inの後にリストを書く
print(i)出力結果はどちらも同じですが、このように書き方もいくつかある場合もあります。
inの後ろに指定できるものとして、他には辞書、タプル、集合などがありますが、ここでは割愛します。
詳しくはこちらの記事で解説していますので良ければ参考にしてください!
whileとの違い
上記に示したプログラムはwhileで書き換えることができます。
i = 0
while i < 10:
print(i)
i = i + 1for文ではinの後ろにリストなどを書きますが、whileの場合は終了条件を書きます。
繰り返しの処理をする際、リストの長さなど明確な終わりがわかる場合はfor、i > 10のように比較演算子などを使ったほうが書きやすい場合はwhileといった使い分けをすると良いでしょう。
使い分けができるようになれば、コードがスッキリと書けるようになるかと思います。
リスト内包表記
Pythonなど一部のプログラミング言語には、繰り返し処理でリストを作る場合、リスト内包表記と呼ばれる書き方が可能です。
名前だけ聞いてもさっぱりだと思いますので、具体例をお見せします。
#通常の書き方
add = []
for i in range(10):
add.append(i + 1) #appendでリスト addにi + 1を追加
print(add)
#出力結果
#[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
#リスト内包表記を使った書き方
add = [i + 1 for i in range(10)]
print(add)
#[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]書き方としては次のとおりです。
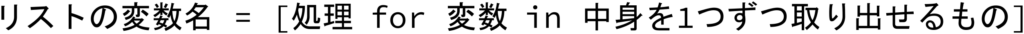
リスト内包表記はコードをスッキリ書くための表記方法なので、煩雑な処理は通常の書き方、1行くらいで書ける処理はリスト内包表記で書くといった使い分けが重要です。
enumerate()の活用
Pythonではenumerate()を使うと、リストの要素と、そのインデックスを同時に取り出すことができます。
まずは具体例を見てみましょう。
add = [i + 1 for i in range(10)]
for i, j in enumerate(add):
print(f"インデックス:{i} リストの中身:{j}")
#出力
# インデックス:0 リストの中身:1
# インデックス:1 リストの中身:2
# インデックス:2 リストの中身:3
# インデックス:3 リストの中身:4
# インデックス:4 リストの中身:5
# インデックス:5 リストの中身:6
# インデックス:6 リストの中身:7
# インデックス:7 リストの中身:8
# インデックス:8 リストの中身:9
# インデックス:9 リストの中身:10このように、enumerate()を使うとリストの何番目に何の数字が入っているかを同時に取り出すことができます。
forを使った実用例
ここではforを使ったサンプルコードをご紹介します。
まずは辞書を使った例です。
例1
scores_dict = {"太郎": [85, 90, 78], "次郎": [72, 88, 91], "三郎": [90, 92, 85]} #辞書
for name, score in scores_dict.items():
average = sum(score) / len(score) #sumで計算したリストの合計/lenで取得したリストの長さ
print(f"{name} の平均点: {average:.2f}")
#出力
# 太郎 の平均点: 84.33
# 次郎 の平均点: 83.67
# 三郎 の平均点: 89.00コードの解説
sorces_dict.items()とすることで辞書のキー、リストでいう所のインデックスとキーに対応した要素を取得できます。
forの内部では辞書から取り出したリストの数値をsum()で合計し、len()でリストの長さ、つまり要素数を取得します。
そして、取得したリストの合計をリストの要素数で割ることで平均値を計算しています。
例2
次に、フォルダ内に保存された画像の大きさを半分にして別フォルダに出力するサンプルコードをご紹介します。
from PIL import Image
import os
import glob as gb
#フォルダ内の画像のパスを取得
input_path = "C://Users//hogehoge//Pictures//img//*" #画像が保存したあるフォルダのパス
filename_list = [n.replace('\\', '//') for n in gb.glob(input_path)]
#画像のファイル名を抽出してリストを作成
filename = [n.replace('C://Users//hogehoge//Pictures//img//', '') for n in filename_list]
#リサイズ後のファイルを出力するフォルダを作成
output_path = "C://Users//hogehoge//Pictures//img//out_put"
#exist_ok=Trueとすると既に存在しているフォルダを指定してもエラーにならない
os.makedirs(output_path, exist_ok=True)
#画像を半分の大きさにリサイズ
for i, f in enumerate(filename_list):
img = Image.open(f)
#img.widthで画像の横幅、img.heightで画像の縦幅を取得
img_resize = img.resize((img.width // 2, img.height // 2))
#qualityは画像の品質を1~100で指定
img_resize.save(output_path + '//' + 'half_' + filename[i], quality=90)コードの解説
globモジュールの使い方については別記事で解説していますので良ければ参考にしてください!
for文より前では、画像をリサイズするための下準備をしています。
基本的にはコードに書いてあるコメントの通りです。
注意点としては、Windowsではパスをコピーしただけですと\\になっているので、//に書き換える必要があります。
そのため、replace()で\\を//に置き換えています。
for文の中では、Image.open()で画像を読み込んでいます。
そして、読み込んだ画像をresize()で画像サイズを半分にして、save()で画像を保存しています。
このコードでは、画像ファイルのパスを保存したリストから画像ファイル名のリストを作っています。
そのため、2つのリストの長さは同じです。
そこで今回は、enumerate()を使って、パスを保存したリストから取り出したインデックスでファイル名のリストの要素を指定しています。
おわりに
今回はforの基本的な使い方をご紹介しました。
より詳しく知りたい部分や、分かりづらかった部分がありましたら、ぜひコメントに書いてください。
最後まで読んでいただきありがとうございました。

コメントを残す コメントをキャンセル