
本記事では、複数の要素を持つデータ型、イテラブルについて解説します!
目次
イテラブルとは
概要
ネットでイテラブルについて調べると、「繰り返し可能なオブジェクト」と出てきます。
他にもイテレーターを生成可能とか色々出てきます。
正直、私はこう聞いても意味がわかりませんでした。
要するに、「for文でinの後ろで使えるやつ」ということらしいです。

イテレータ
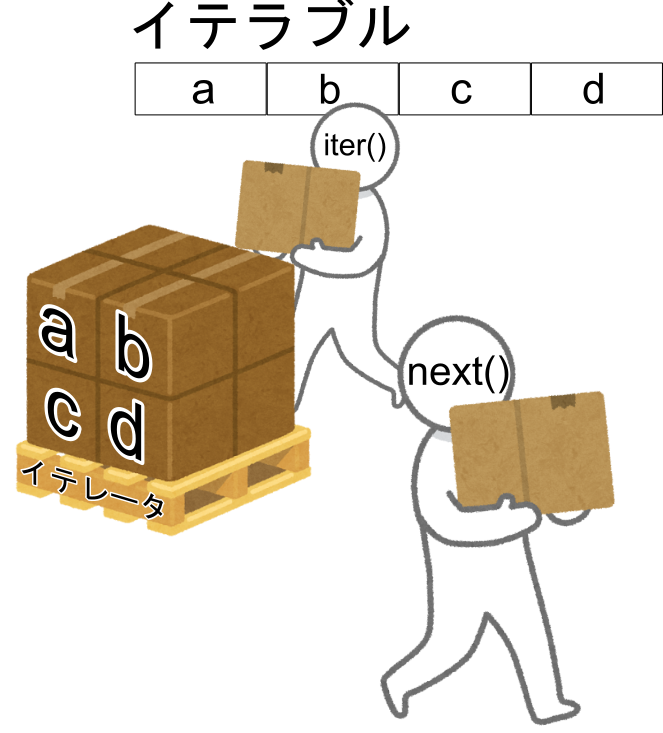
イテレータはイテラブルから作成できる、イテラブルのコピーのような存在です。
イテラブルからiter()を使って作成し、next()を使って中身を順番に取り出せます。
私は、イテラブルは内容を示す表、イテレータは表を見て作った荷物とイメージしています。
作った荷物をnext()を使って取り出すといった感じです。
イテレータは荷物なので取出したらなくなってしまいます。
実際のコードを見てましょう。
sample_list = [i for i in range(3)] #リスト(イテラブル)を作成
sample_iter = iter(sample_list) #iter()を使ってイテレータを作成
print(next(sample_iter))
print(next(sample_iter))
print(next(sample_iter))
#出力
# 0
# 1
# 2ここで、さらにprint(next(sample_iter))を追加してみましょう。
sample_list = [i for i in range(3)] #リスト(イテラブル)を作成
sample_iter = iter(sample_list) #iter()を使ってイテレータを作成
print(next(sample_iter))
print(next(sample_iter))
print(next(sample_iter))
print(next(sample_iter))
#出力
# 0
# 1
# 2
#エラー
#例外が発生しました: StopIteration今回作成したリストの長さは3ですが、それ以上取り出そうとするとエラーが発生します。for文ではこのイテレータを作ったり、このエラーが発生したら自動でループを終了するといった処理が行われているようです。
イテラブルの紹介
具体的には、以下のようなものがイテラブルに属します。
リスト
リストの作り方は簡単です。
sample_list = [0, 'abc', [1, 2]] #リストの作成
print(sample_list) #リストの中身を確認
print(type(sample_list)) #sample_listのデータ型を確認
#出力
# [0, 'abc', [1, 2]]
# <class 'list'>変数名を宣言して、[]の中にリストにしたい要素を「,」で区切って書くだけです。
リストの中身は数字でも文字列でもリストでも可能です。
リストの中身は空でも可能です。
sample_list = []
print(sample_list)
#出力
#[]その場合出力も空になります。
連続したデータでリストを作りたい場合はリスト内包表記を使うといいでしょう。
リスト内包表記についてはこちらの記事でご紹介していますので良ければ参考にしてください!
タプル
リストと似た形式のデータに、タプルがあります。
タプルの作り方は以下の通りです。
sample_list = (1, 'abc', (1, 2, 3))
print(sample_list)
print(type(sample_list))
#出力
# (1, 'abc', (1, 2, 3))
# <class 'tuple'>変数名を宣言して、()の中にタプルにしたい要素を「,」で区切って書くだけです。
カッコは必須ではありませんが、可読性の観点からタプルであることをわかりやすくするためにカッコは付けたほうがいいかと思います。
タプルの中にもタプルを入れることも可能です。
ルールという観点でのリストとの違いは、要素の変更ができない点です。
使い分けという観点では、Pythonの公式ドキュメントには次のように書いてあります。
タプルはリストと似ていますが、たいてい異なる場面と異なる目的で利用されます。タプルは 不変 で、複数の型の要素からなることもあり、要素はアンパック(この節の後半に出てきます)操作やインデックス (あるいは
namedtuplesの場合は属性)でアクセスすることが多いです。一方、リストは 可変 で、要素はたいてい同じ型のオブジェクトであり、たいていイテレートによってアクセスします。引用元:https://docs.python.org/ja/3/tutorial/datastructures.html#tuples-and-sequences
また、私が調べた限りでは、「自分がデータをどのように扱いたいか」によって使い分けるのが良いようです。
例えば、「名前」「年齢」「スコア」のように、複数のデータを組み合わせとして扱いたい場合はタプル、大勢の人のスコアをまとめて処理したい時はリスト、といった感じで使い分けるみたいです。
辞書
辞書の特徴は、単なる要素の集まりではなく、各要素がキーと要素の組み合わせになっている点です。
実際に例を見てみましょう。
sample_list = {'val':1, 1:[1, 2, 3], (3, 4, 5):(1, 2, 3)}
print(sample_list)
print(sample_list[1])
print(type(sample_list))
#出力
# {'val': 1, 1: [1, 2, 3], (3, 4, 5): (1, 2, 3)}
# [1, 2, 3]
# <class 'dict'>キーには文字列や数字等を使えますが、リストは使えません。
for文で使う場合にはitems()メソッドを使うことで、キーと要素を同時に取り出せます。
sample_list = {'val':1, 1:[1, 2, 3], (3, 4, 5):(1, 2, 3)}
for key, value in sample_list.items():
print(f"{key}:{value}")
#出力
# val:1
# 1:[1, 2, 3]
# (3, 4, 5):(1, 2, 3)集合
中括弧「{}」でかこみ、要素を「,」で区切ることで作成できます。
sample_list = {'a', 'a', 1, (1, 2, 3)}
print(sample_list)
print(type(sample_list))
#出力
# {1, 'a', (1, 2, 3)} #aが2つあったので1つ無視されている
# <class 'set'>リストやタプルと違い、集合の場合は重複している要素は無視されます。
また、順番の概念がないので、集合を作成したときの順番は保持されず、出力では順番が崩れていることがわかるかと思います。
順番の概念が無いので、リストのように要素をインデックス等で指定して取り出すことはできません。
文字列
文字列もイテラブルに含まれます。
サンプルコードを見てみましょう。
sample_list = 'abcd'
print(sample_list)
print(type(sample_list))
for x in sample_list:
print(x)
#出力
# abcd
# <class 'str'>
# a
# b
# c
# dこのように、文字列から文字を1つずつ取り出すことができます。
おわりに
今回は以上です。
いろいろなデータ型がイテラブルに分類され、for文で使えることがわかったかと思います。
より詳しく知りたい部分や、わかりづらい所がありましたら、ぜひ教えて下さい!
最後まで読んでいただき、ありがとうございました。

コメントを残す コメントをキャンセル