
みなさんはデータ整理は好きですか?私は大嫌いです。単調な作業を延々と繰り返すのがとても退屈です。
そこで今回は、フォルダの中のcsvを一括で加工して1つのExcelファイルとして出力する方法を紹介します。
動作環境:Windows11 64ビット Python 3.12.0
具体的な内容は以下の通りです。
目次
フォルダ内のcsvファイルのパスを取得
今回は標準モジュールのglobモジュールを使います。
フォルダ内のパスを以下のようにして取得します。
import glob as gb
path_list = gb.glob("C://Users//hogehoge//glob_test//*.csv")
print(path_list[0])
#出力 C://Users//hogehoge\data1.csv
ファイル名を*.csvとすることで、フォルダ内のcsvファイルのパスをリストで取得できます。
ここで1つ問題があります。
パスをよく見ると、区切りが//の部分と\の部分がありますね。
Windowsではパスの区切りが\(環境によって表示が\と\の場合がありますが同じです)ですが、これはpythonでは予期せぬ動作につながる場合があるそうです。
replace()メソッドを使って\を//に置き換える処理をします。
\はそのまま書くとエラーになるので\\と書いてください。
path_list[0] = path_list[0].replace('\\', '//')使い方はreplace(置き換えたい文字列, 置き換え後の文字列)です。
これをfor文を使ってリストの全てに同じ処理を施します。
for i in range(len(path_list)):
path_list[i] = path_list[i].replace('\\', '//')データ処理からExcelファイルとして出力まで
今回はこんな感じのサンプルデータを使用します。
time input output
0 0 1
0.1 0 2
0.2 0 3
0.3 1 4
0.4 1 4
0.5 1 5
0.6 1 5
0.7 0 5
0.8 0 6
0.9 0 6
今回は読み込んだファイルのinputとoutputの合計をまとめて1つのExcelファイルとして出力してみます。
ファイルのパスを取得すると同時にファイル名も取得しておきます。
replace()メソッドでファイル名以外の文字列を除去します。
path_list = gb.glob("C://Users//hogehoge//glob_test//*.csv")
file_name =[]
for i in range(len(path_list)):
path_list[i] = path_list[i].replace('\\', '//') #パスを取得
file_name.append(path_list[i].replace('C://Users//hogehoge//glob_test//', '').replace('.csv', '')) #ファイル名を取得取得したパスを使ってcsvを順番に読み込み、必要なデータを処理した後、新たなデータフレームに格納していきます。
データ処理は一例なのでお好きな処理を書いてください。
for i in range(len(path_list)):
data = pd.read_csv(path_list[i]) #csv読み込み
index = ['input', 'output']
columns = [file_name[i]] #ファイル名から列名のラベルを作成
add_data = [np.sum(data['input']), np.sum(data['output'])] #列(input, output)の値の合計
#############################################################################################
#以下処理したデータをデータフレームに格納する処理
#############################################################################################
if i < 1:
df = pd.DataFrame(add_data, index, columns = [columns[i]]) #新たなデータフレームを作成
else:
df[columns[0]] = add_dataループの1周目にデータ格納用のデータフレームを作ります。
新しいデータフレームはpd.DataFrame(格納するデータ, index = 行名, columns = 列名)で作れます。
格納するデータ、行名、列名は配列で指定してください。
2周目以降は作ったデータフレームにデータを追加していくだけです。
データの追加はdf[列名] = 追加するデータで追加できます。
indexとcolumnsの指定は任意です。どちらか片方だけの指定も可能です。指定しなかった場合は0から順番に振られます。
あとはExcelファイルとして出力するだけです。
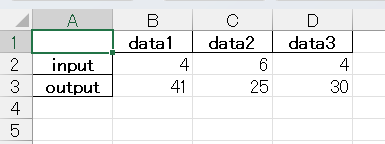
df.to_excel("C://Users//hogehoge//glob_test//data.xlsx")to_excel()メソッドでExcelファイルとして出力できます。
出力結果はこんな感じです。
おわりに
今回は以上です。大量のデータを一気に処理したいときに役立つかと思います。より簡単な方法などありましたらコメントいただければ幸いです。


コメントを残す コメントをキャンセル